Most technology evaluations for large-scale statement production focus on the wrong question. The question banks ask - "can the system generate 150,000 PDFs?" - has become almost trivially easy to answer. Most modern document generation platforms pass this test. The harder questions are operational: can you name every file correctly, route every document to the right recipient, pause the batch so a human can review the full output before it goes out, handle the 23 accounts that failed without stopping the 149,977 that didn't, and confirm to the regulator exactly when investor number 12,847 received their statement?
These are not technology challenges. They are operational requirements, and they need to be designed into a quarterly statement workflow from the start - not retrofitted when the first full-scale run encounters them in production.
This article covers what those requirements look like, why each one exists, and what good operational design for a bank's quarterly statement cycle actually involves.
What Scale Means in a Banking Statement Cycle
When a bank says "quarterly statements at scale," the numbers vary considerably by institution - but the operational structure is consistent. A mid-size asset manager running investor statements might process 10,000 to 50,000 individual PDFs per quarter. A retail bank with current account customers might run in the hundreds of thousands. A large fund administrator running statements across multiple funds could be in the millions.
The number matters less than what it implies. Each document is unique - different investor, different holdings, different valuations, different transaction history. Each must reach a specific recipient. Each is legally significant: it is the bank's formal communication of a customer's financial position for the period. And each is repeatable: if a regulator or a customer disputes the content two years from now, the bank must be able to reproduce the exact document that was sent.
That last requirement - reproducibility - shapes the entire architecture. It means the data used to generate each statement must be preserved at generation time. The template version used must be recorded. The parameters must be logged. The output must be traceable from the filed copy back through the generation event to the frozen input data.
This is what distinguishes banking-grade quarterly statement production from general-purpose batch reporting. The output is not just a document. It is an evidence artefact.
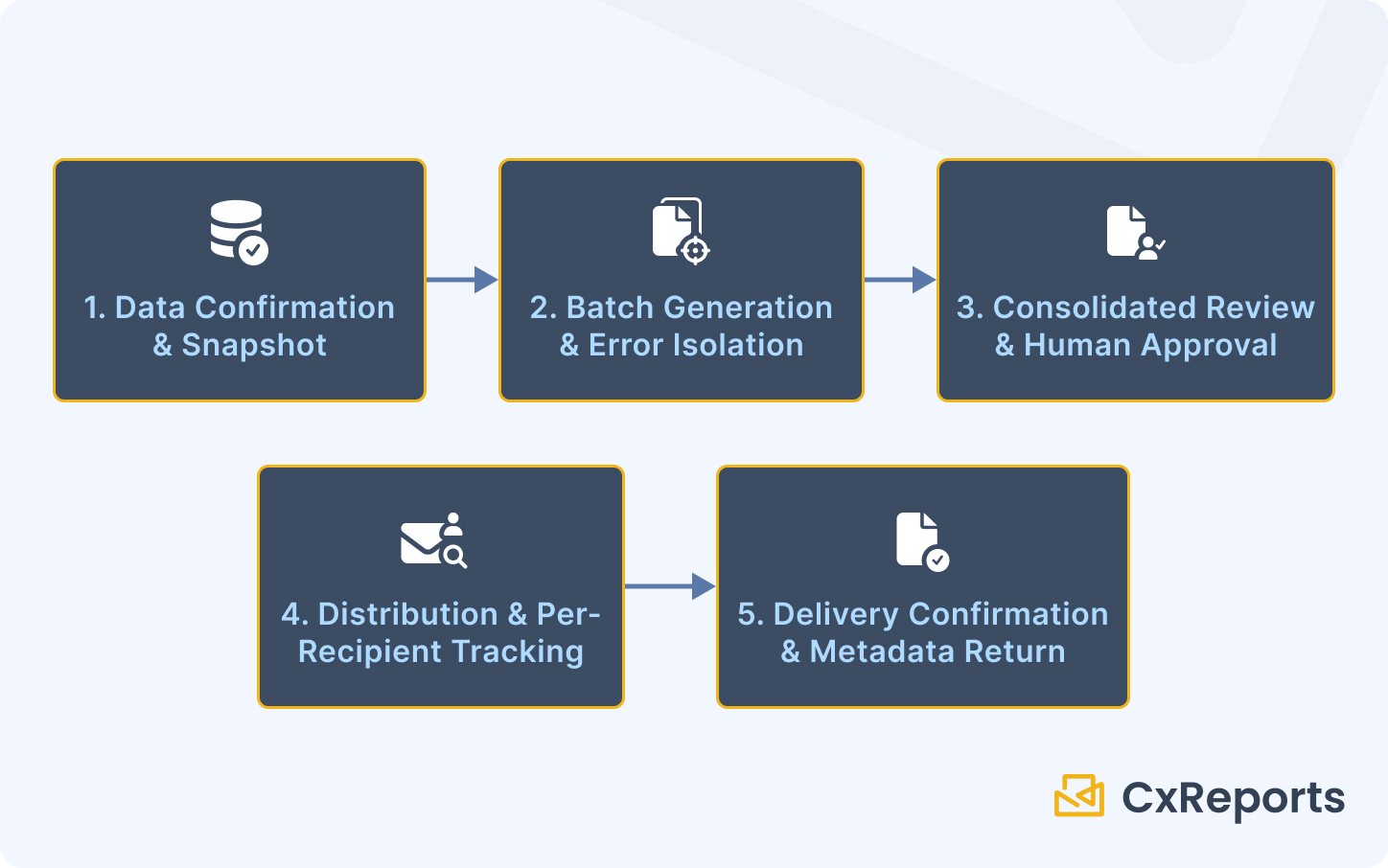
Six Operational Requirements That Determine Whether a Batch Run Is Fit for Production
1. File Naming and Folder Structure
In a quarterly statement run, the output organisation is not cosmetic. File names and folder structures are how downstream systems - archiving platforms, regulatory document stores, CRM integrations, and manual exception handling teams - find, retrieve, and process individual documents.
A file named report_14582.pdf tells a reviewer nothing. A file named ARION-INVESTORS-Q1-2026-ACC-14582-SMIRNOVA-E.pdf placed in a folder structure like /2026/Q1/investor-statements/ tells an operations team member exactly what they are looking at and where it belongs.
This matters at scale because retrieval is as important as generation. When a customer service agent receives a complaint about a statement, they need to locate the exact document within seconds. When an auditor asks for a sample of 50 statements from a specific quarter, the folder structure should make that pull trivial rather than requiring a database query.
Naming conventions and folder structures should be defined before a statement run goes live - and they should reflect how the operations team and downstream systems actually work, not what the report generation tool produces by default.
2. Data-Driven Recipient Resolution
At 10,000 investors, manually configuring recipient email addresses is already operationally impractical. At 150,000, it is impossible. The recipient list must come from the data.
Data-driven recipient resolution means the statement run draws its distribution list directly from the same data that feeds the reports. Each investor record includes their contact details. The email job reads those details and maps each generated document to its intended recipient without a human assembling a spreadsheet.
This has two implications beyond pure convenience. First, it eliminates the category of error where a statement is sent to the wrong address because a manually maintained distribution list is out of date. Second, it means the link between a specific document and a specific recipient is traceable - because both come from the same data record.
There is an important discipline here: the data that drives recipients should be frozen in the same snapshot as the data that feeds the reports. A recipient address that changes after the snapshot date should not affect the current run. The run distributes to the address that was on record when the data was confirmed.
3. The Data-Ready Trigger
The quarterly statement run should not start because a clock reached a scheduled time. It should start because the data is ready.
This is a subtle but important distinction. Period-end data is almost never finalised at a predictable time. Custodian feeds are late. Valuations require end-of-day prices that take hours to confirm. A corporate action applied incorrectly needs a manual correction before the positions are right. Running a batch generation job against unconfirmed data produces statements that will need to be corrected and rerun - a more expensive and operationally disruptive outcome than simply waiting.
The right pattern is an explicit data-readiness signal. Someone responsible for the data - a reconciliation team, a data operations manager, a portfolio accounting system - confirms that the period-end data is correct, complete, and frozen. That confirmation is the trigger for generation.
This pattern also improves the audit trail. "The statement run was triggered after data confirmation at 14:32 on 31 March" is a more defensible record than "the scheduled job ran at 2:00am on 1 April regardless of whether data was ready."
Depending on the operational architecture, this trigger might be a manual approval action in a workflow system, a data-readiness status flag emitted by an upstream platform, or an explicit API call made after reconciliation is signed off.
4. The Consolidated Review Pack
Before a single statement reaches an investor's inbox, a human reviewer needs to confirm the batch is correct. This is a regulatory and operational requirement, not optional quality assurance.
The challenge is that no operations team can open 150,000 individual PDFs. The consolidated review pack solves this. It is a single document - or a navigable review interface - that presents the full batch output in a format that allows meaningful sampling and spot-checking.
A reviewer using a consolidated pack is not trying to read every statement. They are checking for systematic errors: a common formatting problem across all statements, a missing disclosure section, incorrect period dates, a zero-value portfolio that should contain positions. These types of errors, which would affect the entire batch, are visible in a consolidated review in seconds. They would be invisible until customer complaints arrived if the batch were distributed without review.
The consolidated review is also a workflow control point. The operations team transitions from "generation complete" to "review complete" to "approved for distribution" as an explicit state change - one that is logged, attributed to a named reviewer, and timestamped. That state transition is part of the evidence record for the run.
5. Error Isolation: One Broken Account Must Not Stop the Others
In any large statement run, some reports will fail. A data exception for a specific account, a missing value in a required field, a portfolio with no transactions in the period when the template expects at least one - these edge cases are unavoidable at scale.
The operational requirement is that these failures are isolated. The 23 accounts with data exceptions should generate error flags and be queued for manual remediation. The other 149,977 statements should generate successfully, pass through the consolidated review, and proceed to distribution on schedule.
This has practical implications for how the batch run is architected. Failures need to produce clear, actionable error messages - not cryptic system errors that require a developer to diagnose. The error log for the run needs to identify the failed accounts, the reason for failure, and the remediation steps. And the successful reports should not be held back waiting for the failed ones to be resolved.
After remediation - which might involve correcting source data, adjusting a template parameter, or manually providing missing values - the failed accounts can be regenerated and distributed in a supplementary run. This supplementary run should follow exactly the same review and approval workflow as the main run.
6. Delivery Confirmation
The statement run is not complete when the last PDF is generated. It is not complete when the email job finishes. It is complete when delivery status per recipient is confirmed and that status is recorded.
For regulated documents, delivery confirmation is not a nice-to-have. If a customer later claims they never received their quarterly statement, the bank needs more than a log entry saying "the email was sent." It needs a delivery record - ideally an SMTP acceptance record from the receiving mail server, along with the timestamp, the recipient address, and the document identifier.
More practically, the delivery failure rate for a 150,000-statement run will not be zero. Addresses change. Inboxes fill. Corporate email servers reject messages during maintenance windows. A defined process for handling delivery failures - retry logic, failure escalation, manual follow-up for regulatory recipients - needs to be part of the operational design before the first full-scale run.
For institutions where the statement run is orchestrated by an upstream system - a workflow platform, an investment management system, or a fund accounting tool - the delivery metadata should flow back to that system. The upstream record for each investor account should reflect whether their statement was successfully delivered, when, and by which mechanism.
The Human Approval Gates That Automation Cannot Remove
Automating the mechanical steps of a statement run - data preparation, report generation, email distribution - does not remove human accountability. In banking, it is not supposed to.
Three explicit approval gates appear in a well-designed statement workflow:
Before generation: data sign-off. Someone confirms the period-end data is correct, complete, and frozen. Generation should not proceed without this confirmation. In many institutions, this sign-off is a formal step in the workflow platform, logged against a named individual with a timestamp.
Before distribution: consolidated review. A named reviewer confirms the batch output is correct. This review uses the consolidated pack to sample output and check for systematic errors. The approval to proceed to distribution is an explicit action, not an automatic transition.
Distribution authorisation. In some institutions and for some document types, the decision to distribute statements to customers - particularly at scale or for regulatory filings - requires a separate authorisation. This is the point at which the operations team formally commits to the external distribution of the run.
These gates are where automation supports humans rather than replaces them. The technology handles the volume and the mechanics. The humans handle the judgment and the accountability.
How This Maps to CxReports
CxReports provides the report generation, scheduling, and distribution infrastructure for a quarterly statement workflow. The following maps each operational requirement to the relevant platform capabilities.
Personalised generation at scale. Report parameters in CxReports accept investor identifiers, period dates, account group references, investor category codes, and other typed values that drive both data queries and presentation logic. A single statement template, parameterised correctly, serves the full investor base with appropriate variation per account.
Data-driven recipients. CxReports email jobs support a data source as the recipient list - the email addresses field can be populated automatically from the same dataset that feeds the report parameters. This connects each generated statement to its intended recipient through the data, not through a manually maintained distribution list.
API-triggered generation. For workflows where an upstream system signals data readiness, CxReports exposes an API for programmatic report generation. An investment management platform, a workflow system, or a custom reconciliation process can call the API to trigger the run after data confirmation - implementing the data-ready trigger pattern without relying on clock-based scheduling.
Subreports for composite statements. Holdings tables, transaction summaries, performance sections, and regulatory disclosure pages can each be implemented as independent subreports, embedded into the parent statement template. Updating a regulatory disclosure is a change to one subreport, not a change to every template.
Themes for branding consistency. For institutions with multiple business units, sub-brands, or institutional investors requiring specific branding, CxReports themes allow a single base template to render with different visual identities without forking the template logic.
Workspaces for isolation. For institutions running statements across multiple fund structures, legal entities, or business units, CxReports workspaces provide clean separation of templates, data sources, and user access. Cross-contamination between entities is prevented at the platform level.
Generation logs. Every report generated through CxReports is recorded: user identity, timestamp, report identifier, and parameter values. This is the generation log that forms one component of the wider evidence record for the run.
What CxReports does not replace is the operational process that surrounds it: the data confirmation step upstream, the consolidated review workflow, the remediation process for failed accounts, and the delivery confirmation records that the bank's operations team maintains as evidence of distribution. These are operational responsibilities that good tooling supports but cannot substitute.
Getting Started with CxReports
| Quarterly statement requirement | CxReports capability |
|---|---|
| Personalised generation per investor (ID, period, account) | Report parameters (Date, Lookup, Text, Number types) |
| Data-driven recipient list | Email data source with email addresses source enabled |
| Holdings table, performance section, disclosures | Subreports - independent, reusable, embedded into parent |
| Multi-brand or multi-entity isolation | Workspaces - independent templates, data sources, users |
| Advisor or fund manager branding | Themes applied per entity or business unit |
| API-triggered generation from upstream systems | CxReports API (GET /api/v1/ws/{workspaceId}/reports/{id}/pdf) |
| Generation traceability | Built-in generation logs (user, timestamp, parameters) |
Documentation:
- Report Parameters
- Subreports
- Email Scheduling and Data-Driven Recipients
- Themes
- Workspaces
- API Reference
If you are evaluating CxReports for a quarterly statement run, book a demo to see the parameterised template and batch delivery workflow against a realistic volume scenario.